¿Te gustaría saber si tu web ha sido usada para entrenar modelos de IA como T5 de Google, o LLaMA de Facebook? 💡
Pues tenemos una herramienta para consultarlo. E incluso podremos saber qué porcentaje de tokens del total se han tomado de cada web incluida en la base de datos.
Empecemos por el principio. C4 es un corpus con textos extraídos de millones de webs en abril de 2019.
Este rastreo es obra de Common Crawl, organización sin ánimo de lucro que cada dos meses crea una "copia" de una parte representativa de internet, pública y disponible para el que quiera consultarla.
Como he dicho, tanto Google como Facebook usaron C4, que sale de un rastreo concreto de Common Crawl, para entrenar algunos de sus modelos.
¿Y OpenAI? Sabemos que OpenAI también usó Common Crawl para entrenar a GPT-3 (confirmado, aunque no sabemos exactamente qué parte) y presumiblemente también lo ha usado para GPT-4, aunque en este caso no tenemos confirmación, ya que ha sido totalmente opaco con los datasets de entrenamiento.
Aún sin tener más detalles, podemos decir que C4 probablemente será bastante similar en su composición al dataset de Common Crawl usado para GPT-3.
Por supuesto, todos los modelos usan fuentes adicionales en su entrenamiento, pero nos sirve para tener una idea del contenido procedente de internet que han usado.
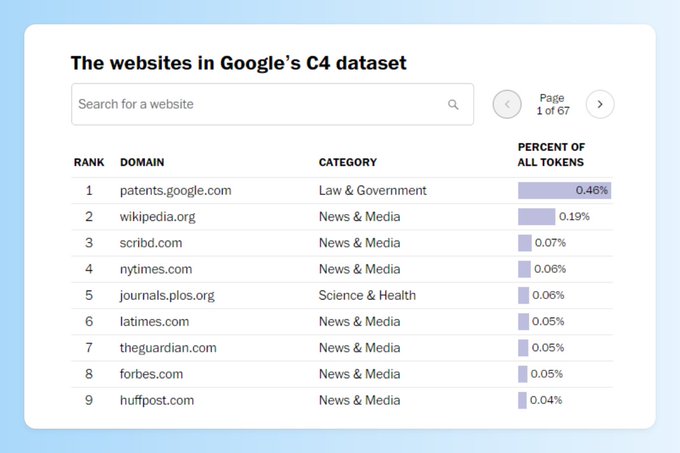
Y ahora a la herramienta: el Washington Post ha publicado un artículo muy completo analizando la composición de este corpus, y lo mejor es que incluye un buscador donde puedes comprobar si tu sitio, o el que tú quieras, está presente en C4 y en qué proporción.
Las webs más usadas dentro de C4 son, en este orden, el directorio de patentes de Google, Wikipedia, Scribd y el New York Times.
En cuanto a temáticas, las principales son Negocios/Industrial con un 16% del contenido, Tecnología con un 15% y Noticias con un 13%, pero claro, casi siempre a partir de webs en inglés.